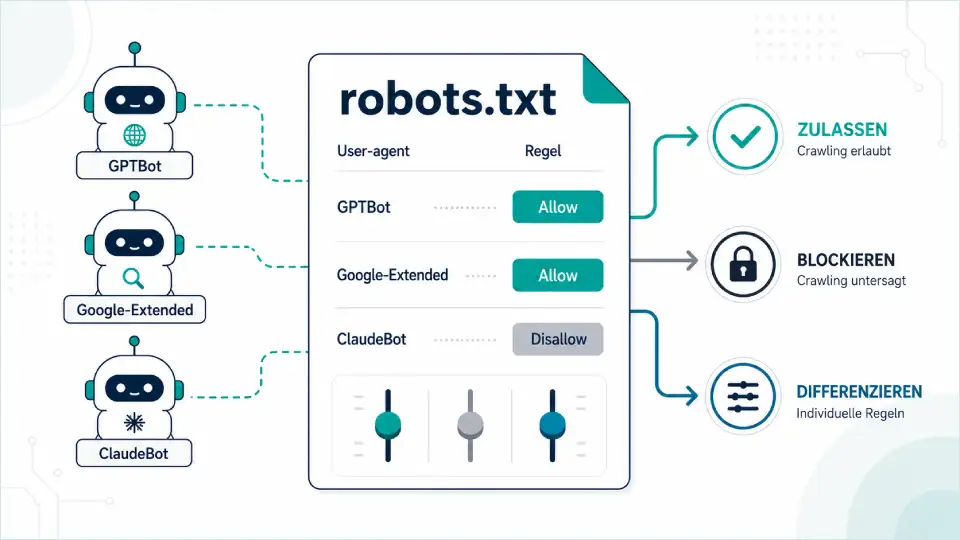
Vor zwei oder drei Jahren war die robots.txt für die meisten Blogger eine Datei, die man einmal aufgesetzt und dann geflissentlich ignoriert hat. Ein paar Angaben für Googlebot, vielleicht ein Disallow auf den Login-Bereich, fertig. Heute steht in dieser unscheinbaren Textdatei plötzlich eine strategische Entscheidung: ob deine Inhalte in ChatGPT, Claude, Gemini oder Perplexity überhaupt noch auftauchen dürfen.
Das ist keine theoretische Frage. Inzwischen blockieren nach einer Auswertung von BuzzStream aus April 2026 rund 79 Prozent der großen Nachrichten-Websites die Trainings-Crawler der KI-Anbieter, und 71 Prozent blockieren sogar die Retrieval-Crawler, also die Bots, die für die Live-Antworten der KI-Chatbots zuständig sind. Was bei einem großen Verlag mit eigener Rechtsabteilung und Lizenzverhandlungen Sinn ergeben kann, ist für einen kleinen Blog meistens die falsche Strategie.
Im großen WordPress-SEO-Überblick für 2026 habe ich das Thema bewusst nur kurz angerissen. Hier gehen wir jetzt ins Detail.
Worum geht es hier?
Bevor wir loslegen, eine kurze Abgrenzung, damit der Artikel nicht ausufert.
Es geht um die robots.txt als das klassische Steuerungsinstrument für Crawler. Nicht um serverseitige Blockaden via Cloudflare-WAF, .htaccess oder Nginx-Regeln. Das sind eigene Themen, die einen eigenen Artikel verdienen. Hier nur so viel: Wenn die robots.txt alleine nicht reicht, weil ein Crawler die Regeln schlicht ignoriert, kommen wir später noch darauf zu sprechen. Aber der Schwerpunkt liegt auf der Datei selbst.
Es geht um deutschsprachige Blogger, kleinere Unternehmen und WordPress-Betreiber, die ihre Seite selbst verwalten.
Es geht hier auch nicht um llms.txt. Das Thema habe ich im besagten Artikel schon eingeordnet, und meine Skepsis bleibt unverändert. 🤓
Inhaltsverzeichnis
- Welche Bots gibt es überhaupt?
- Training vs. Retrieval: die eigentliche Trennlinie
- Drei strategische Optionen
- Praxisteil: drei robots.txt-Beispiele
- Wann die robots.txt nicht reicht
- Ein kurzer Blick auf die rechtliche Seite
- Meine Empfehlung
- Häufige Fragen
Welche Bots gibt es überhaupt?
Bevor wir zur strategischen Frage kommen, lohnt sich ein kurzer Blick darauf, wer da so alles an deine Tür klopft. Ich gehe das nach Anbieter durch, weil du am Ende deine robots.txt auch in solchen Blöcken aufbaust: erst alle OpenAI-Bots, dann alle Anthropic-Bots, dann alle Google-Bots.
Eine Vollständigkeitsgarantie gibt es nicht. Die Landschaft ändert sich schnell, neue Anbieter kommen dazu, alte werden umbenannt. Ich konzentriere mich auf die fünf Anbieter, die für deutschsprachige Blogger 2026 praktisch relevant sind.
OpenAI
OpenAI hat drei Bots im Einsatz und dokumentiert sie sauber:
- GPTBot ist der Trainings-Crawler. Wer ihn blockiert, sorgt dafür, dass künftige Modellversionen die eigenen Inhalte nicht mehr lernen.
- OAI-SearchBot ist der Such-Crawler, der Inhalte für die Suchfunktion in ChatGPT indexiert. Wer hier blockiert, fällt aus den Suchantworten in ChatGPT heraus.
- ChatGPT-User wird ausgelöst, wenn ein ChatGPT-Nutzer aktiv eine URL anklickt oder einen Link in den Chat einwirft. OpenAI weist explizit darauf hin, dass die robots.txt hier nicht zwingend greift, weil es als User-Aktion gilt und nicht als automatisches Crawling.
Anthropic
Anthropic war lange Zeit etwas unübersichtlich mit den User-Agents anthropic-ai und claude-web. Diese alten Namen sind mittlerweile durch eine klar dokumentierte Dreiteilung ersetzt:
- ClaudeBot ist der Trainings-Crawler.
- Claude-SearchBot indexiert für die Such- und Antwortfunktionen.
- Claude-User wird durch eine konkrete Nutzeranfrage ausgelöst.
Anthropic gibt explizit an, dass alle drei Bots die robots.txt respektieren, auch der user-initiierte Claude-User. Das ist eine bewusste Differenzierung gegenüber den Mitbewerbern.
Bei Google wird es interessant, weil die meiste Verwirrung hier entsteht.
Googlebot ist der klassische Crawler für die Web-Suche. Er ist auch der Crawler hinter den AI‑Overviews, also den KI-Zusammenfassungen, die Google seit 2024 oberhalb der klassischen Treffer einblendet. Wer aus AI‑Overviews verschwinden will, kann das nicht über die robots.txt steuern, ohne sich gleichzeitig aus der gesamten Google-Suche zu schießen.
Google-Extended ist hingegen kein eigener Crawler, sondern nur ein Steuer-Token. Google sagt das selbst klipp und klar: Es gibt keinen eigenen User-Agent-String, keinen eigenen Crawl-Vorgang. Du kannst per Disallow: / für Google-Extended steuern, ob die bereits durch Googlebot gecrawlten Inhalte für das Training von Gemini und für Vertex AI verwendet werden dürfen. Auf das Ranking in der Google-Suche und auf das Erscheinen in den AI‑Overviews hat das keinen Einfluss.
Diese Unterscheidung ist wichtiger, als sie auf den ersten Blick aussieht. Wir kommen weiter unten noch darauf zurück.
Perplexity
Perplexity hat zwei Bots, offiziell dokumentiert:
- PerplexityBot baut den Index auf, aus dem Perplexity seine zitierten Antworten zusammensetzt. Befolgt die robots.txt.
- Perplexity-User wird durch eine konkrete Nutzeranfrage ausgelöst und ignoriert die robots.txt nach eigener Aussage – ähnlich der OpenAI-Logik.
Common Crawl
Etwas im Hintergrund, aber relevant: Die Non-Profit-Organisation Common Crawl betreibt den CCBot und stellt ihre monatlich aktualisierten Datensätze frei zur Verfügung. Viele kleinere AI-Anbieter und Forschungsprojekte trainieren ihre Modelle auf diesen Daten, anstatt selbst zu crawlen. Wer CCBot blockiert, schneidet damit eine ganze Reihe von Modellen mit ab, ohne dass deren Anbieter selbst auf der Liste stehen müssen.
Andere Anbieter wie Bytespider von ByteDance, Meta-ExternalAgent oder Amazonbot existieren ebenfalls, sind aber für die deutschsprachige Blogosphäre weniger zentral. Wer sie blockieren möchte, ergänzt seine robots.txt sinngemäß.
Training vs. Retrieval: die eigentliche Trennlinie
Die meisten Anleitungen, die du im Web findest, listen die Bots auf und gehen weiter. Aber genau hier liegt der Knackpunkt, an dem viele Betreiber ihre robots.txt falsch konfigurieren. Die wichtige Frage ist nämlich nicht, welche Bots du blockierst, sondern zu welchem Zweck sie unterwegs sind.
Grob lassen sich drei Kategorien unterscheiden:
- Trainings-Crawler sammeln Inhalte, die später in das Training neuer Modellversionen einfließen. Wer hier blockiert, verhindert, dass die eigenen Texte in künftigen GPT-, Claude- oder Gemini-Versionen verarbeitet werden. Auf die aktuellen KI-Antworten hat das keinen direkten Effekt. Die Modelle sind ja schon fertig trainiert.
- Retrieval- oder Search-Crawler holen Inhalte für die Live-Antworten der KI‑Suche. Sie sind der Grund, warum ChatGPT oder Perplexity dich überhaupt in einer Antwort zitieren können. Wer hier blockiert, fällt sofort und sichtbar aus den KI-Antworten heraus.
- User-initiierte Fetcher werden ausgelöst, wenn ein Mensch aktiv eine URL in die KI-Oberfläche packt oder einen Link anklickt. Hier wird es interessant: Ob die robots.txt überhaupt greift, hängt vom Anbieter ab.
Diese letzte Kategorie ist der Punkt, den viele Artikel unter den Tisch fallen lassen. Anthropic sagt klar, dass auch der user-initiierte Claude-User die robots.txt respektiert. OpenAI und Perplexity sagen ebenso klar, dass ihre user-initiierten Bots (ChatGPT-User, Perplexity-User) die robots.txt unter Umständen ignorieren.
Die Begründung ist nachvollziehbar: Wenn ein Mensch aktiv eine URL eintippt, gilt das als Nutzerhandlung, nicht als automatisches Crawling. Aber die praktische Konsequenz ist eine andere als bei den Trainings-Bots: Auch ein vermeintlich vollständiger Block hat hier seine Lücken.
Wer also pauschal sagt »Ich blockiere alle KI-Bots« und einfach GPTBot, ClaudeBot und PerplexityBot auf Disallow: / setzt, hat in Wirklichkeit nur die Trainings-Crawler ausgesperrt. Die Such-Crawler (OAI-SearchBot, Claude-SearchBot) laufen weiter, und die user-initiierten Bots tun, was sie tun. Umgekehrt: Wer alle drei Kategorien blockiert, ist in den KI-Antworten praktisch unsichtbar – und das ist 2026 eine teurere Entscheidung als noch vor zwei Jahren.
Klingt erst einmal nach Detailfrage, ist aber in der Praxis der Grund, warum so viele Site-Betreiber ihre robots.txt mit dem Gefühl »Ich habe alles richtig gemacht« geschlossen haben und sich anschließend wundern, dass sie trotzdem (oder gerade deshalb) nicht mehr in ChatGPT auftauchen.
Drei strategische Optionen
Mit der Unterscheidung zwischen Training und Retrieval im Hinterkopf lassen sich drei realistische Strategien formulieren. Keine davon ist universell richtig. Welche zu dir passt, hängt davon ab, was du erreichen willst und welche Rolle KI-Sichtbarkeit für dein Projekt spielt.
Standard: zulassen
Für die meisten Blogger und kleineren Unternehmen ist die einfachste und in meinen Augen auch sinnvollste Option, alle relevanten Crawler grundsätzlich zuzulassen. Der Hintergrund: Wer ohnehin schon mit dem Rückgang organischer Klicks durch AI Overviews und Zero-Click-Searches zu kämpfen hat (und das ist 2026 so ziemlich jeder), sollte sich nicht zusätzlich auch noch die Sichtbarkeit in den KI-Antworten verbauen. Zu diesem Thema habe ich im Artikel zu den Zero-Click-Searches und in ChatGPT SEO: Die Evolution des Suchbegriffs schon einiges geschrieben.
Klar, das bedeutet auch, dass die eigenen Inhalte in künftige Trainingsdurchläufe einfließen. Wer das aus prinzipiellen Gründen ablehnt, hat ein starkes Argument. Aber für die meisten Blogprojekte überwiegt der Sichtbarkeitsvorteil. Die großen Verlage, die aktuell pauschal blockieren, haben eine andere Ausgangslage: eigene Lizenzverhandlungen mit AI-Anbietern, eigene Rechtsabteilungen, eigene Reichweite. Das ist für einen Ein-Personen-Blog kaum der passende Maßstab.
Ausnahme 1: technische Notwehr
Es gibt einen Fall, in dem auch ich blockieren würde: Wenn ein Crawler den Server hämmert. ClaudeBot hatte 2024 mehrere Wochen lang einen unrühmlichen Ruf, weil er auf einigen Seiten dermaßen aggressiv zugegriffen hat, dass die Betreiber Performance-Probleme bekamen. Auch andere Bots können das gelegentlich tun, vor allem wenn sie auf eine frisch aktualisierte Sitemap stoßen.
Aber das ist keine prinzipielle Entscheidung gegen KI, sondern Ressourcenschutz. Bevor man hier mit einem harten Disallow: / antwortet, lohnt sich der Blick auf die Crawl-delay-Direktive. Anthropic unterstützt sie explizit, Google ignoriert sie zwar, aber bei den meisten anderen Anbietern ist sie ein guter Mittelweg.
Ein einfaches Beispiel:
User-agent: ClaudeBot
Crawl-delay: 10Damit sagst du dem Bot: »Lass bitte zehn Sekunden zwischen den Anfragen verstreichen.« In den meisten Fällen reicht das aus.
Ausnahme 2: bewusste Trennung
Die dritte Option ist die interessanteste und in meinen Augen die unterschätzteste: Du blockierst gezielt das Training, lässt aber die Retrieval-Crawler durch. Damit verhinderst du, dass deine Inhalte in künftige Modelle einfließen, bleibst aber in den aktuellen KI-Antworten sichtbar.
Genau hier kommt die Google-Sache ins Spiel, die ich oben angedeutet habe. Wer Google-Extended auf Disallow: / setzt, blockiert das Training von Gemini. Die Google-Suche bleibt davon unberührt, und auch die AI Overviews funktionieren weiter, weil sie über Googlebot laufen. Wer also einerseits in der Google-Suche und in den AI‑Overviews sichtbar bleiben, andererseits aber nicht ungefragt in Gemini-Modelle einfließen will, hat hier eine saubere Trennlinie.
Bei OpenAI funktioniert das ähnlich: GPTBot blockieren stoppt das Training, OAI-SearchBot zulassen erhält die Sichtbarkeit in der ChatGPT‑Suche. Bei Anthropic kannst du ClaudeBot blockieren und Claude-SearchBot zulassen. Ein praktikabler Ansatz, der allerdings etwas mehr Pflege verlangt, weil du wissen musst, welcher Bot zu welchem Zweck unterwegs ist.
Praxisteil: drei robots.txt-Beispiele
Wir haben jetzt die Theorie und die strategische Einordnung. Schauen wir uns an, wie das konkret in der robots.txt aussieht.
Ein kurzer technischer Hinweis vorab: WordPress liefert seit einigen Versionen eine dynamisch generierte robots.txt aus dem Core. Wer eigene Regeln einbauen will, hat zwei Optionen. Entweder legt man eine physische robots.txt ins Hauptverzeichnis der Domain (die hat dann Vorrang), oder man nutzt die entsprechende Funktion des SEO‑Plugins. The SEO Framework hat dafür einen eigenen Bereich in den Einstellungen, Yoast und Rank Math ebenfalls. Im Zweifel bitte selbst nachschauen, weil sich die Plugin-Oberflächen schnell ändern können.
Option 1: alle zulassen
Das ist die Standard-Empfehlung für einen Großteil der Blogger. Im Kern reicht es, die wichtigsten Bots explizit zu erwähnen und ihnen den vollen Zugriff zu geben:
User-agent: GPTBot
Allow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: Claude-User
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Perplexity-User
Allow: /
User-agent: Google-Extended
Allow: /
User-agent: CCBot
Allow: /
Streng genommen müsstest du die Bots nicht einmal namentlich aufführen, weil ohne explizite Disallow-Regel sowieso alles erlaubt ist. Rein theoretisch würde also auch das hier ausreichen:
User-agent: *
Allow: /Aber die explizite Nennung hat zwei Vorteile: Erstens dokumentiert sie deine Entscheidung, falls du sie später revidieren willst. Zweitens schützt sie davor, dass eine spätere User-agent: *-Regel mit einem versehentlichen Disallow alles mit ausschließt.
Option 2: Training blockieren, Retrieval zulassen
Das ist die differenzierte Variante für alle, die in den KI-Antworten sichtbar bleiben wollen, aber nicht ungefragt in Trainingsdaten einfließen möchten:
# Training blockieren
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
# Retrieval und Suche zulassen
User-agent: OAI-SearchBot
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
Was diese Konfiguration bewirkt: Deine Inhalte fließen nicht mehr in das Training künftiger Modelle ein. Zumindest nicht über die offiziellen Crawler der genannten Anbieter. Aber wenn jemand ChatGPT, Claude oder Perplexity nach einem Thema fragt, das du behandelt hast, kann dein Beitrag weiterhin zitiert werden.
Wichtig: Die user-initiierten Bots (ChatGPT-User, Perplexity-User) habe ich hier bewusst weggelassen, weil sie die robots.txt sowieso nicht zuverlässig respektieren. Wer sie aufnehmen will, kann das tun, sollte sich aber nicht zu viel davon versprechen.
Option 3: alle blockieren
Die kompromisslose Variante. Sie ist technisch die einfachste, aber praktisch die teuerste, weil sie die KI-Sichtbarkeit komplett kappt:
User-agent: GPTBot
Disallow: /
User-agent: OAI-SearchBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Claude-SearchBot
Disallow: /
User-agent: Claude-User
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Perplexity-User
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
Wer das einsetzt, sollte sich darüber im Klaren sein, dass die Sichtbarkeit in ChatGPT, Claude, Gemini und Perplexity damit weitgehend auf Null geht. Für Verlage mit eigener Verhandlungsposition gegenüber AI-Anbietern kann das eine Strategie sein. Für die meisten Blogger ist es meiner Meinung nach keine gute Strategie.
Übrigens: Googlebot taucht in keinem der drei Beispiele auf. Das ist Absicht. Googlebot steuert die klassische Web-Suche und die AI‑Overviews. Wer den blockiert, fliegt aus der Google-Suche raus, und das will hier vermutlich niemand.

Wann die robots.txt nicht reicht
Bei aller Detailliebe sollte man eines nie aus dem Auge verlieren: Die robots.txt ist ein Hinweisschild, kein Schloss. Sie funktioniert nur, weil die meisten Anbieter sich daran halten. Wer das nicht tut, dem ist mit einer Textdatei nicht beizukommen.
Drei Punkte, die man bedenken sollte:
- Aggressive Scraper ignorieren die Regeln. Bytespider von ByteDance ist hier das Standardbeispiel, aber es gibt eine ganze Reihe weniger bekannter Crawler, die ihre eigenen Regeln machen. Wer wirklich Daten will, dem ist die robots.txt egal.
- Spoofing ist trivial. Ein gefälschter User-Agent ist mit einer Zeile Code geschrieben. Anbieter wie OpenAI, Anthropic und Perplexity veröffentlichen deshalb IP-Bereiche, über die sich ihre Bots verifizieren lassen. Wer ganz sicher gehen will, prüft die IP und nicht den User-Agent.
- Für harten Schutz braucht es Serverebene. Wer einen Crawler wirklich aussperren will, etwa weil er den Server überlastet oder weil man rechtliche Gründe hat, kommt um serverseitige Lösungen nicht herum. Cloudflare-WAF, Nginx-Regeln, gezielte IP‑Sperrungen. Das ist ein eigenes Thema.
Kurz gesagt: Die robots.txt ist der Höflichkeitsmodus des Webs. Sie funktioniert für die freundlichen Bots, und das sind erfreulicherweise die meisten der großen Namen. Aber sie ist kein Garant.
Ein kurzer Blick auf die rechtliche Seite
Ich bin kein Anwalt und das hier ist keine Rechtsberatung, sondern eine Einordnung aus Praktikersicht. Wer es genauer wissen will, findet bei seriösen Fachquellen wie der IAPP oder bei den großen Anwaltskanzleien detaillierte Analysen.
Die Lage in der EU lässt sich grob so zusammenfassen: Die DSM-Richtlinie von 2019 erlaubt Text- and Data-Mining (TDM), wenn der Rechteinhaber nicht widerspricht. Dieser Widerspruch muss »in maschinenlesbarer Form« erfolgen, und die robots.txt gilt als einer der akzeptierten Wege. Der EU‑AI-Act verpflichtet Anbieter von General-Purpose-AI-Modellen, dieses Opt-out zu respektieren, und der dazugehörige GPAI Code of Practice nennt robots.txt explizit als anerkannten Mechanismus.
Soweit die Theorie. In der Praxis ist gerade einiges in Bewegung: Das OLG Hamburg hat im Dezember 2025 im Fall Kneschke gegen LAION zwar Stellung zu maschinenlesbaren Opt-outs bezogen, die Revision zum BGH ist aber zugelassen. Und der CJEU hat im März 2026 die erste mündliche Verhandlung im Fall »Like Company gegen Google« geführt, in dem es um die Frage geht, ob KI-Training überhaupt unter die TDM-Ausnahme fällt. Mit einer endgültigen Klärung würde ich in den nächsten Monaten nicht rechnen.
Für die Praxis heißt das: Eine Disallow: / für einen Trainings-Crawler in der robots.txt ist ein etablierter Weg, das Opt-out auszudrücken. Sie schützt aber nur vor Anbietern, die sich daran halten, und nur für künftige Crawls. Was bereits in einem Modell verarbeitet wurde, lässt sich nachträglich nicht herauslösen. Mal schauen, was die nächsten Gerichtsentscheidungen daraus machen.
Meine Empfehlung
Wenn ich das Ganze auf einen praktischen Nenner bringen soll, dann sieht meine Linie so aus:
Im Standardfall lasse ich die KI-Crawler zu. Die Sichtbarkeit in ChatGPT, Claude, Gemini und Perplexity ist 2026 ein realer Faktor, und wer sich aus prinzipiellen Gründen aussperrt, verliert mehr, als er gewinnt. Das gilt vor allem für kleinere Blogs und Unternehmen, die ohnehin schon mit dem Rückgang organischer Klicks zu kämpfen haben.
Wenn ein Bot wirklich Stress macht, also den Server überlastet oder unverhältnismäßig oft zugreift, dann solltest du ihn blockieren. Aber das ist eine Ressourcen-Entscheidung, keine prinzipielle. Vor dem harten Disallow: / lohnt sich der Blick auf Crawl-delay, sofern der Anbieter das unterstützt.
Wer das Training stören, aber in den KI-Antworten sichtbar bleiben will, kann die differenzierte Trennung wählen: Trainings-Crawler raus, Retrieval- und Search-Crawler rein. Das ist mehr Pflegeaufwand, aber eine valide Position für alle, die sich grundsätzlich nicht mit ihren Inhalten an Modellen beteiligen wollen, ohne sich gleich aus der Sichtbarkeit zu schießen.
Und ein letzter Punkt, der mir wichtig ist: Bevor du irgendwas in deine robots.txt schreibst, sei dir bewusst, was du damit konkret abschaltest. Wer GPTBot blockiert, blockiert nicht ChatGPT als Ganzes, sondern nur das Training. Wer Google-Extended blockiert, blockiert weder die Google-Suche noch die AI-Overviews, sondern nur das Gemini-Training. Wer alle drei OpenAI-Bots blockiert, fliegt aus der ChatGPT-Suche komplett raus.
Wie schaut es bei euch aus? Habt ihr eure robots.txt schon auf die neue KI-Welt angepasst, lasst ihr noch alles offen, oder seid ihr beim differenzierten Modell gelandet? Habt ihr Bots beobachtet, die sich nicht an die Regeln halten? Ich freue mich über eure Erfahrungen in den Kommentaren.
Häufige Fragen
Muss ich die robots.txt auch für meine Subdomains separat anlegen?
Ja. Die robots.txt gilt immer nur für genau den Host, auf dem sie liegt. Wenn du also example.com und blog.example.com betreibst, brauchst du zwei getrennte Dateien. Anthropic weist in seiner Doku ausdrücklich darauf hin, dass das Opt-out für jede Subdomain einzeln eingerichtet werden muss. Wer einen WordPress-Multisite-Aufbau mit Subdomains betreibt, sollte das auf dem Schirm haben.
Was passiert mit Inhalten, die bereits in einem Modell verarbeitet wurden, wenn ich jetzt blockiere?
Nichts. Eine nachträgliche Sperrung in der robots.txt wirkt nur in die Zukunft. Was bereits in die Gewichte eines neuronalen Netzes eingeflossen ist, lässt sich technisch nicht herauslösen – dafür müsste das Modell von Grund auf neu trainiert werden. Wer also seit Jahren bloggt und jetzt erst auf Disallow: / umstellt, sperrt damit künftige Trainingsdurchläufe aus, nicht aber die bestehenden Modelle. Common Crawl ist hier besonders unangenehm: Was einmal im Archiv ist, bleibt dort, und dieses Archiv reicht zurück bis 2008.
Reicht es, die KI-Crawler im SEO-Plugin zu konfigurieren, oder muss ich an die robots.txt direkt ran?
Beides funktioniert. Yoast, Rank Math und The SEO Framework können die robots.txt ausgeben und um eigene Regeln ergänzen. Solange du keine physische robots.txt im Hauptverzeichnis liegen hast, bedient sich WordPress des dynamisch generierten Inhalts der Plugins. Sobald aber eine echte Datei im Root liegt, hat die Vorrang und überschreibt alles, was die Plugins ausspucken. Bei größeren Setups mit mehreren Plugins, die alle gleichzeitig an der robots.txt mitschreiben wollen, ist die physische Datei oft die klarere Lösung.
Habe ich einen SEO-Nachteil bei Google, wenn ich Google-Extended blockiere?
Nein. Google sagt das in der eigenen Doku ziemlich deutlich: Google-Extended hat keinen Einfluss auf das Ranking in der Web-Suche. Es steuert ausschließlich, ob deine Inhalte für das Training von Gemini und für Grounding-Funktionen in Vertex AI verwendet werden dürfen. Auch die AI‑Overviews bleiben unberührt, weil die über Googlebot laufen. Wer also auf der einen Seite in der Google-Suche und in den AI‑Overviews präsent bleiben, sich aber gegen Gemini-Training entscheiden will, hat mit Disallow: / für Google-Extended eine saubere Lösung.



Danke für die ausführliche Erklärung, da muss ich wohl endlich mal wieder ran an meine robots 😀
Danke für diesen sehr ausführlichen und informativen Beitrag! Für Unternehmenswebsites ist eine differenzierende robots.txt sicher die sinnvollste Lösung. Auf meinen privaten Websites nutze ich mittlerweile nur noch die Block List für Apache/.htaccess von Jeff Starr. https://perishablepress.com/ultimate-ai-block-list/#block-ai-via-apache