Der Vorteil einer langen Berufserfahrung, speziell im Web-Bereich, ist, dass du viele Comebacks erlebst. Manche sind erwartbar und andere wiederum passen gut in die Serie »Wer hätte das gedacht?«.
Zu der letzten Gruppe würde ich Markdown einsortieren. Es existiert seit knapp 22 Jahren, und hier müssen wir ehrlich sein: Bis vor zwei bis drei Jahren war diese (leichte) Auszeichnungssprache lediglich einer gewissen Schicht von IT-Nerds wirklich bekannt, und auch nicht alle von denen haben sie tatsächlich regelmäßig genutzt.
Und das, obwohl diese Sprache auf Plain-Text (reiner, »nackter« Text) basiert und daher ohne spezielle Programme und Editoren auf so ziemlich allen Systemen lesbar und bearbeitbar ist. Sieh dazu auch meinen Blogartikel aus 2013.
Markdown ist eine gelungene Mischung aus Einfachheit, einer ordentlichen Anzahl an Auszeichnungen und Formatierungen und einer sehr hohen Verfügbarkeit … Und erst durch die KI, hat es Markdown aus der gemütlichen und ländlich geprägten Nerd-Kleinstadt in die weite Welt geschafft.
Ich kenne einige Leute, die bis vor ein paar Monaten nicht wussten, was Markdown ist, und die heute mit großen Markdown-Dateien hantieren, als ob die das schon immer getan hätten. Es werden umfangreiche Systemprompts für ChatGPT, Claude und Grok erstellt, Skills für Claude generiert und Anweisungen für n8n geschrieben.
Open Knowledge Format von Google Cloud
Und das ist nicht alles. Google Cloud hat vor einigen Tagen das Open Knowledge Format (OKF) vorgestellt, welches auf Markdown basiert. Der Inhalt wird als Verzeichnis von Markdown-Dateien abgelegt, jeweils mit einem kleinen YAML-Vorspann für die Metadaten. Das Ganze steht unter der Apache-2.0-Lizenz und liegt aktuell als Version 0.1 vor.
Im Grunde wird durch OKF etwas in eine Spezifikation gegossen, das vorher schon herumgeisterte. Andrej Karpathy hatte, soweit ich mich erinnern kann, im April 2026 die Idee eines »LLM-Wikis« skizziert.
Das ist unter anderem deswegen interessant, weil Google Search erst wenige Wochen zuvor, Mitte Mai 2026, in seinem ersten Leitfaden zur KI-Suche ausdrücklich gesagt hatte, man benötige für die öffentliche Suche weder llms.txt noch irgendein KI-Markup noch Markdown-Versionen von der eigenen Website.
Ein echter Widerspruch ist das nicht, die öffentliche Suche und das interne Organisieren von Wissen sind zwei unterschiedliche Baustellen. Zumindest auf den ersten Blick. Aber eine gewisse Unstimmigkeit ist dennoch da, und sie sagt mehr, als man denkt. Für das Wissen, das KI-Agenten sauber konsumieren sollen, greift derselbe Konzern dann doch zu Markdown.
Wer tiefer in die Crawler-Frage einsteigen will, dem empfehle ich meinen Artikel zu KI-Crawlern und der robots.txt. OKF, llms.txt und Markdown für Agenten gehören imho thematisch in dieselbe Schublade.
Die KI bringt den Wendepunkt
Aber wie hängen die KI und Markdown zusammen? Warum ausgerechnet dieses nischige Text-Format?
- Die Trainingsdaten: Die großen Sprachmodelle haben beim Training Markdown überall vorgefunden. GitHub ist voll davon. READMEs, Dokumentationen etc. Dann andere Plattformen wie Stack Overflow, Reddit und andere Foren. Markdown war hier stark vertreten. Für die LLMs somit ein bekanntes Format.
- Die Token-Effizienz: Jedes Zeichen kostet Rechenleistung und belegt Platz im Kontextfenster. Eine Markdown-Überschrift verbraucht weniger Tokens als das HTML-Gegenstück mit seinen Tags und das noch ganz ohne die
div-Verschachtelungen, Navigationselemente und Skripte drumherum. Kurz: Weniger Gepäck = mehr Inhalt pro Anfrage. - Die Steuerungsdateien: Die Dateien, mit denen du KI-Werkzeuge heute konfigurierst und anweist, sind Markdown.
CLAUDE.md,SKILL.md,AGENTS.mdvon OpenAI usw. Das Format wird inzwischen in einer großen Zahl von Projekten genutzt. Markdown ist somit von der nerdigen Auszeichnungssprache zur wichtigen Auszeichnungssprache geworden.
Hinzukommen dann auch so »Kleinigkeiten« wie die llms.txt. Sie macht im Prinzip für die KI das, was die robots.txt für die Suchmaschinen-Crawler macht. Eine kleine, schnörkellose Textdatei mit Markdown-Auszeichnungen als Tourguide für die KI.
Und was wird aus BBCode, Textile und Co.?
Wenn Markdown gewinnt, dann ist die Frage naheliegend, was aus den Geschwistern & Cousins wird. Die (leichten) Auszeichnungssprachen waren nie eine homogene Einheit. Hier ein schneller Überblick über den momentanen Stand der nahen Markdown-Verwandtschaft:
BBCode ist 1998 herausgekommen, eine vereinfachte HTML-Umsetzung in eckigen Klammern, fest verbunden mit den Foren-Systemen wie phpBB, vBulletin & Co. Wie alt diese Werkzeugfrage ist, sieht man daran, dass ich schon 2011 über ein Firefox-Add-on namens BBCodeXtra geschrieben habe.
BBCode hat praktisch keine Editor-Unterstützung, und wichtige Werkzeuge wie Pandoc können damit nichts anfangen. Da es an die Foren-Welt gebunden ist, ist auch die Popularität von BBCode an die Popularität von Foren gebunden.
Hier ein kleines Beispiel von BBCode:
Ich bin [b]fett[/b] und ich [i]kursiv[/i].
Daraus wird dann in der Ausgabe:
Ich bin fett und ich kursiv.
Textile wurde kurz vor Markdown eingeführt und ist nie richtig populär geworden. Heute darf man es getrost als erledigt betrachten.
AsciiDoc ist der interessante Fall. Es kann einiges mehr als Markdown und eignet sich gut für die Ausgabe in mehrere Formate, also HTML, PDF, DocBook und so weiter. Bei technischen Büchern und API-Referenzen ist es beliebt und lebendig. Aber es ist und bleibt eine gut gepflegte, aber überschaubare Nische.
reStructuredText hält sich hartnäckig, vor allem als Standard im Python-Umfeld über Sphinx, das große Projekte wie Django oder NumPy dokumentiert. Aber hier gibt es Bewegung: Über den MyST-Parser liest Sphinx inzwischen auch Markdown. Viele neue Sphinx-Projekte starten direkt in MyST und schreiben gar kein reST mehr. Der Standard rutscht also Richtung Markdown.
Markdown überholt oder zieht Teile der Verwandtschaft zu sich. Nicht weil es das mächtigste Werkzeug wäre, sondern weil es das ist, was am Ende überall verstanden wird. Es wäre nicht das erste Mal in der Tech-Geschichte, dass sich nicht das leistungsfähige, sondern das populäre Modell durchsetzt.
Werkzeuge: vom Browser bis WordPress
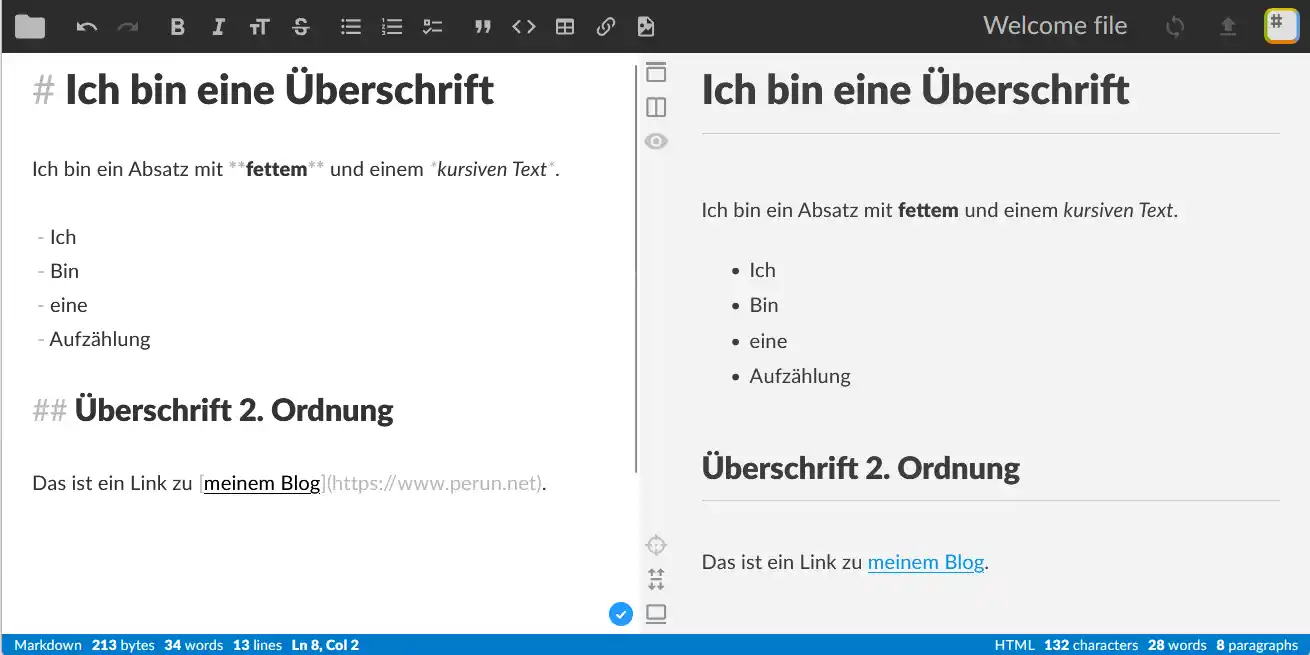
Klar, du kannst dir einen beliebigen Text-Editor nehmen und anfangen, Markdown zu schreiben. Für viele ist das ausreichend. In der Praxis brauchst du aber schon eine gewisse Syntaxunterstützung und Vorschau. Ein guter webbasierter Einstieg ist StackEdit. Wer Desktop-Anwendungen bevorzugt, der wird dann in Visual Studio Code oder Sublime Text fündig. Wenn schon nicht nativ, dann kannst du dort mit Erweiterungen so Sachen wie eine Vorschau nachrüsten. Der Editor Zed steht schon seit einiger Zeit auf meiner Test-Liste.
Mit Obsidian, welches auf Markdown setzt, kannst du sogar deine komplette Wissensdatenbank organisieren. Ich bin mir ziemlich sicher, dass es draußen noch etliche Werkzeuge gibt, aber ich wollte diesen Artikel nicht noch mehr ausufern lassen.
In WordPress ist Markdown seit Jahren kein Neuland mehr. Über das Jetpack-Modul war Markdown im WordPress schon vor über zehn Jahren möglich. Wie hier die Sache mit den anderen Plugins ist, habe ich offen gesagt seit ein paar Jahren nicht mehr beobachtet.
Wie schaut das bei euch aus? Nutzt ihr Markdown nur bei der KI oder auch bei der Erstellung von anderen Texten? Welche Tools nutzt ihr?